![[자료구조] 스택 예제, 중위 표기(infix)를 후위 표기(postfix)로 변환하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FVLbAm%2Fbtrb7z56KHB%2FuXtwbyT1fO3Bj7CZmYGae0%2Fimg.png)

목표
스택을 활용해서 중위 표기법으로 입력한 연산을 후위 표기법으로 변환해서 결과를 출력하는 프로그램을 작성해보겠습니다.
목차 클릭하면 해당 목차로 이동합니다.
스택 예제 : 중위 표기법을 후위 표기법으로 변환하여 계산하는 계산기
개요
저번 포스팅에서 스택에 대해서 복습했습니다. 스택은 LIFO(Last In First Out) 구조를 갖는 자료구조입니다. 마치 접시와 같이 마지막에 들어간 데이터가 맨 처음 나오는 구조로, 파이썬의 클래스를 활용해서 구현했습니다. 클래스 안에 멤버 리스트를 생성해서 append, pop 함수로 스택을 만들었습니다.
이번 포스팅에서는 스택을 활용해서 중위 표기(infix)로 입력된 수식을 후위 표기(postfix)로 바꾸고 계산하는 프로그램을 작성해보도록 하겠습니다. 보통 수식 연산을 할 때 우선순위가 존재합니다. 덧셈, 뺄셈보다는 곱셈, 나눗셈을 먼저 하는 것입니다. 파이썬이나 C언어 같은 프로그래밍 언어를 배울 때도 연산자의 우선순위를 배우는데요. 컴파일할 때, 어느 연산자를 먼저 처리할지 정해놓은 일종의 약속입니다. 그래서 중위 표기로 적어도 우리가 원하는 결과를 얻을 수 있습니다. 하지만, 스택을 활용하기 위해서 중위 표기로 적은 수식을 후위 표기로 변환해서 계산하는 과정을 진행하도록 하겠습니다.
수식 표기법
계산기 코딩을 시작하기에 앞서 수식 표기법에 대해서 이해하고 넘어가겠습니다.
수식이란, "1 + 2 * 3" 처럼 수학 연산식을 말합니다. 평소에는 저런 형태의 수식만을 봤을텐데, 사실 수식을 표기하는 방법은 3가지나 있습니다. 이제 하나씩 들여다볼 건데, 필요한 단어들에 대해서 알아보겠습니다.
"1+2 * 3" 이라는 연산에서 "1, 2"와 같이 계산이 되는 숫자(기호)를 피연산자(Operand)라고 하고, " +, * "와 같이 계산하는 것을
연산자(Operator)라고 합니다. 연산자는 단항 연산자, 이항 연산자 등이 있는데요. 연산 시 필요한 피연산자의 수에 따라서 나누는 것입니다. 이름처럼 단항 연산자는 피연산자가 1개, 이항 연산자는 피연산자가 2개가 필요합니다.
단항 연산자는 ++, --, (-5), (+5) 와 같은 것들이 있고, 이항 연산자는 +, -, * 등이 있습니다.
그럼 표기법에 대해서 알아볼까요?
전위 표기법(Prefix Notation)
전위 표기법은 연산자를 모두 피연산자의 앞으로 적는 표기법입니다.
"1 + 2 * 3" 와 같은 수식을 "+ 1 * 2 3"과 같이 피연산자 앞에 연산자를 표기하는 것입니다. 방법은 다음과 같습니다.
방법
①. 연산자 우선순위에 맞게 괄호를 쳐준다. → ( 1 + ( 2 * 3 ) )
②. 괄호 안에 있는 연산자들을 바로 옆 괄호 앞으로 빼준다. → + ( 1 * ( 2 3 ) )
③. 모든 괄호를 제거한다. → + 1 * 2 3
중위 표기법(infix Notation)
중위 표기법은 우리가 평소에 사용하는 것처럼 피연산자 사이에 연산자를 넣어 표기하는 방법입니다.
예시 : 1 + 2 * 3
후위 표기법(Postfix Notation)
후위 표기법은 전위 표기법과 유사하지만 연산자를 피연산자의 뒤에 표기하는 방법입니다.
마찬가지로 "1 + 2 * 3"을 후위 표기법으로 표시하면 다음과 같습니다.
방법
①. 연산자 우선순위에 맞게 괄호를 쳐준다. → ( 1 + ( 2 * 3 ) )
②. 괄호 안에 있는 연산자들을 바로 옆 괄호 뒤로 빼준다. → ( 1 ( 2 3 ) * ) +
③. 모든 괄호를 제거한다. → 1 2 3 * +
이렇게 수식 표기법에 대해서 알아보았습니다. 이 표기법을 활용해서 계산기를 만들어보도록 하겠습니다.
스택 예제 : 중위 표기법을 후위 표기법으로 바꿔서 계산하는 계산기
스택 구조를 활용해서 중위 표기법으로 표기한 수식을 후위 표기법으로 변환해서 계산하는 계산기를 제작해보도록 하겠습니다. 입출력은 다음과 같습니다.
입력 : 2 + 3 * 5 ( 중위 표기법 )
출력 : 2 3 5 * + ( 후위 표기법 ), 계산 결과
문제를 해결하기 위해서는 1개의 스택과 1개의 리스트가 필요합니다. 수식이 입력되면 스택에 후위 표기법으로 변환해서 쌓습니다. 맨 위에 있는 데이터(Top)를 뺐을 때 피연산자면 리스트에 옮깁니다. 그러다가 연산자가 나올 경우 리스트에 있는 데이터 중 최근 2개의 데이터를 빼서 연산을 진행하고 결과를 리스트에 다시 쌓습니다.
후위 표기법으로 변환해서 스택에 쌓이면 다음과 같습니다.

Top에 있는 데이터가 2입니다. 이걸 다른 리스트에 저장하고 계속해서 데이터를 Pop 합니다.
그러다 * 연산자가 나오면 리스트 위에 있는 피연산자 3과 5에 대해 * 연산을 진행하고 다시 리스트에 쌓습니다. 그럼 리스트에는 15와 2가 남을 텐데요. 그리고 스택에서 +를 꺼내서 리스트에 있는 2와 15를 더하면 결국 리스트에는 계산 결과인 17이 남고, 스택은 비어있는 상태로 프로그램을 종료하게 됩니다.
이 과정을 진행하기 위해 스택 클래스와 3개의 함수가 필요합니다. 스택 클래스는 이전 게시글에서 다뤘으니 생략하고 함수를 보겠습니다.
참고 : [자료구조] 스택(Stack)이란? 스택을 활용해 괄호쌍 확인하기
토큰화(Tokenization)
먼저 수식을 입력받으면, 문자열 형태로 입력받게 됩니다. 이 문자열에서 연산자와 피연산자를 분리해야 합니다.
이렇게 문자열과 같은 문장에서 의미가 있는 최소 단위로 쪼갠 것을 "토큰"이라고 합니다.
입력 예시의 "2 + 3 * 5"에서 각각 2, +, 3, *, 5는 모두 의미가 있는 것들입니다. 연산을 위해 하나씩 쪼개서 리스트에 입력할 필요가 있습니다. 이 과정을 토큰화라고 합니다.
토큰화를 진행하는 함수를 확인해보겠습니다.
메소드를 보면 "expr"을 매개변수로 받습니다. 이건 그냥 입력받은 수식을 매개변수로 받는 것입니다.
먼저 빈 리스트인 temp, 결과를 저장할 result라는 리스트를 선언했고, 문자열 num을 선언했습니다.
입력받는 숫자가 두 자리 이상일 수 있기 때문에, 연산자가 나오기 전에는 한 숫자로 간주하고 덧셈 연산을 통해서 합쳐서 temp에 저장하는 것입니다. 그러다 연산자가 나오면 한 단어로 간주하고 float형으로 변환해서 결과 리스트에 넣는 것입니다. (나눗셈 연산 등을 위해서 실수형으로 변환했습니다.)
반복문이 이렇게 종료되면 맨 마지막에 있는 피연산자는 결과 리스트에 추가하지 않습니다. 연산자일 경우에만 내부 반복문(for j in temp:)에 접근할 수 있게 만들었기 때문입니다. 그래서 반복문(for i in expr:)이 종료되면 temp에 남아있는 마지막 피연산자를 num에 담아서 한 개의 피연산자로 만들고 결과 리스트에 넣어서 리턴합니다.
보시면 알겠지만, "+, -, *, /, (, )" 연산자만 입력받는다고 가정하고 작성한 코드입니다. 연산자를 추가하는 것은 그냥 적으면 되겠지만, 실수를 입력받는다면 조금 수정할 필요가 있을 것 같네요.
중위 표기법 후위 표기법으로 변환하기(Infix to Postfix)
이제 입력받은 수식을 각각 분리해서 리스트에 담았습니다. 이제 이 수식을 후위 표기법으로 변환해서 리스트에 담아야 합니다. 연산자의 우선순위를 확인해서 우선순위가 높은 게 위로 오게 해야 합니다. 그림으로 봤을 때, 스택의 위에서만 넣고 뺄 수 있으니 낮은 우선순위의 연산자를 넣어야 할 땐 높은 걸 빼고 넣는 과정을 거쳐야 합니다.
함수를 보면서 확인해보겠습니다.
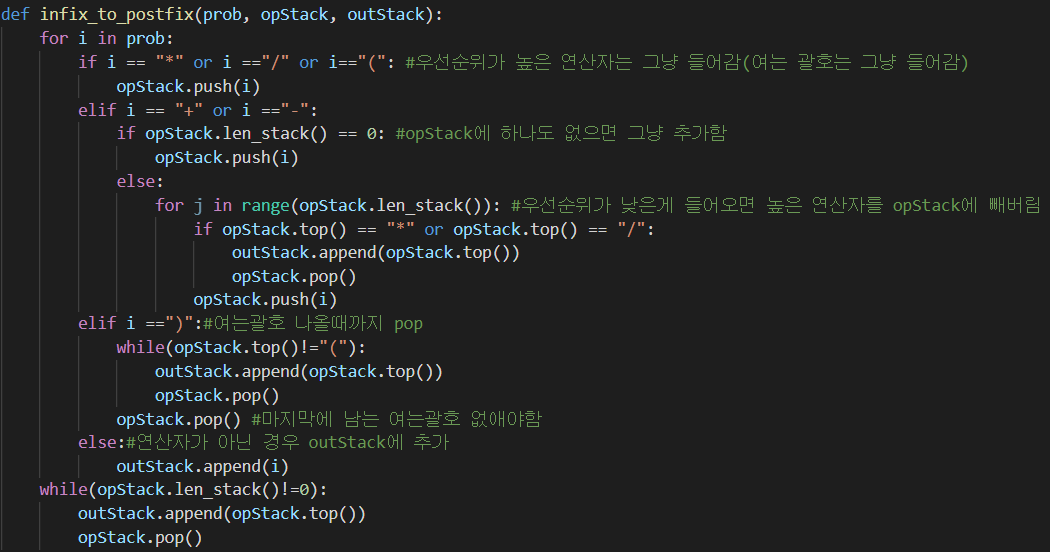
먼저 매개변수로 3개를 받습니다. 방금 토큰화를 진행한 리스트(prob), 스택(opStack), 후위 표기법으로 저장할 리스트(outStack)를 매개변수로 받습니다.
저희는 위에서 입력받을 연산자를 정해놨기 때문에 어떤 연산자가 우선순위가 높은지 알고 있습니다. 이에 따라서 코드를 작성할 수 있습니다.
토큰화를 진행한 리스트에서 우선순위가 높은 "*, /" 연산자가 나오면 스택에 그대로 넣습니다.
"+, -"와 같이 우선순위가 낮은 것이 들어오면 스택의 Top을 확인합니다.(그 아래에는 정리가 되어 있으니까요.) 높은 우선순위의 연산자가 있으면 opStack으로 빼버립니다. 그리고 낮은 우선순위의 연산자(+,-)를 outStack에 넣습니다.
그리고 수식을 입력받을 때, 괄호가 사용된 수식들이 있습니다. ex : 2 + (3 - 1 )
실제로도 연산자 우선순위에서 괄호는 상당히 높은 우선순위를 갖습니다. 일단, 여는 괄호가 나오면 우선 스택에 쌓습니다. 그러다 닫는 괄호가 나오면 스택에서 여는 괄호가 나올 때까지 다 Pop하여 outStack에 넣습니다. 이렇게 쌓으면 괄호 안에 있는 연산 먼저 진행하겠죠?
그리고 피연산자(숫자)의 경우에는 바로 outStack으로 옮겨 담습니다.
이렇게 되면 outStack에는 후위 표기법으로 정리된 수식이 저장되게 됩니다.
리스트의 값을 바꾼 것이기 때문에 따로 리턴은 하지 않습니다.(void)
+ 우선순위가 낮은 연산자가 들어왔을 경우, 높은 연산자를 빼는 과정에서 반복문이 사용되었습니다.
for j in range(opStack.len_stack()):이런 문장이 사용이 되었는데, 다음과 같이 적는 게 더 올바르지 않았을까 싶습니다.
while(opStack.len_stack()):일단 j를 사용할 일이 없고 단순히 반복만 하기 때문에, 이게 더 효율적이었을 것 같습니다.
후위 표기법으로 정리된 수식 계산
이제 outStack에는 후위 표기법으로 정리된 수식이 저장되어 있습니다.
위에서 데이터를 하나씩 꺼내면서 연산자가 나오면 최근에 나온 피연산자 2개를 계산하여 다시 값을 스택에 넣습니다.
이를 반복하면 계산 결과가 나오게 됩니다.
함수를 확인해보겠습니다.
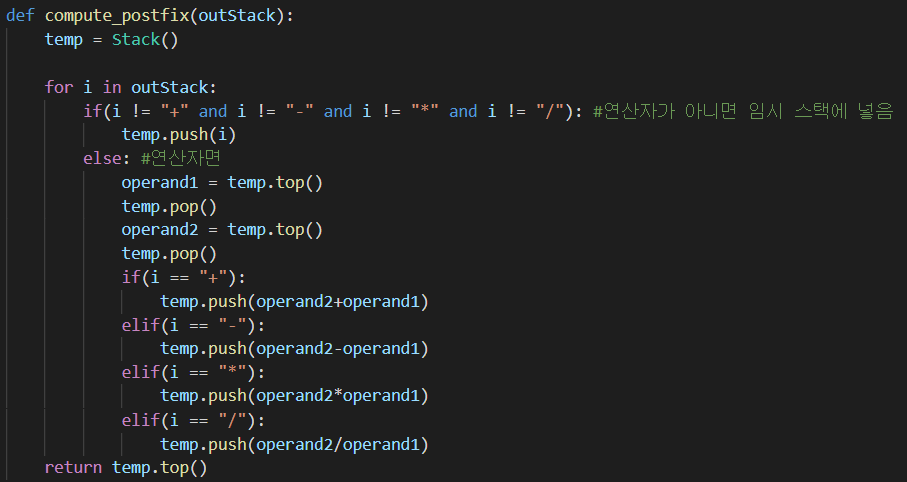
연산을 하기 위해 빈 스택을 생성했습니다. 만약, 연산자가 아닐 경우(피연산자일 경우) 빈 스택에 임시로 저장합니다.
그러다 연산자가 나오면 빈 스택의 위에 있는 두 개의 피연산자를 계산하고 다시 빈 스택에 넣어놓습니다.
빈 스택은 피연산자를 모아놓는 역할을 하고 outStack에 있는 연산자와 계산하는 것입니다.
결국, 빈 스택에는 결과만 남게 되기 때문에 Top을 리턴하면 계산 결과가 나오게 됩니다.
제대로 결과가 출력되는지 확인해보겠습니다.

입력받은 수식을 후위 표기법으로 변환해서 제대로 된 결과를 출력하는 모습을 확인할 수 있습니다.
정리
크게 어려운 내용은 아니었지만, 생각보다 시간이 오래 걸렸습니다. 큰 틀에는 문제가 없었지만 사소한 부분들이 자꾸 발목을 잡는 기분이 들었습니다. 조금 더 많은 알고리즘 문제들을 풀면서 기초를 다져야 할 필요성을 느끼는 예제였던 것 같습니다.
가만 보면, 굳이 스택이라는 자료구조를 사용해서 새로운 빈 스택을 만들어서 옮겨서 담고 하는 번거로운 과정들이 추가된 것 같이 보일 수 있다고 생각합니다. (실제로 그렇게 생각했었습니다.) 하지만, 이런 자료구조를 사용해서 프로그램을 체계적으로 짠다면 더 좋은 성능을 보입니다. 다른 사람들과 협업할 때, 이해하기 좋다는 장점이 있습니다.
다음 포스팅에서는 "큐"라는 자료구조에 대해서 다루도록 하겠습니다.
*한국외대 신찬수 교수님의 Data Structures with Python 강의를 참고하여 포스팅하였습니다.
'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기 (0) | 2021.08.23 |
|---|---|
| [자료구조] 큐(Queue)란? (0) | 2021.08.19 |
| [자료구조] 스택(Stack)이란? 스택을 활용해 괄호쌍 확인하기 (0) | 2021.08.11 |
| [자료구조] 순차적 자료구조, 배열과 리스트의 이해 (0) | 2021.08.10 |
| [자료구조] 피보나치 수열의 시간 복잡도 완벽히 이해하기 (1) | 2021.08.03 |
![[자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FJtZ0V%2FbtrjPNnSwEB%2Fck92cL1LlcM46FASUTKFIK%2Fimg.png)
![[자료구조] 큐(Queue)란?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbyJG3q%2FbtrcB4Cu3S6%2FzyvKG5T1nvsSK5whcKp3ZK%2Fimg.png)
![[자료구조] 스택(Stack)이란? 스택을 활용해 괄호쌍 확인하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F3Xs32%2FbtrbLd2jPQq%2FJK93n2kZIn4KS3cHaQDn60%2Fimg.png)
![[자료구조] 순차적 자료구조, 배열과 리스트의 이해](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdBOj7d%2FbtrbCt5y8tl%2Fw8obdMKZDYwYE5rkZkRA81%2Fimg.png)