![[자료구조] 양방향 연결리스트(Doubly Linked List), 원형 양방향 연결리스트(Circularly doubly Linked List)](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FwSzHf%2FbtrjO4KxZXK%2FBSvMog360xBGq5hG1M8gWK%2Fimg.png)

목표
단방향 연결 리스트에 이어 양방향 연결리스트에 대해서 알아보도록 하겠습니다.
목차 클릭하면 해당 목차로 이동합니다.
양방향 연결 리스트(Doubly Linked List)
원형 양방향 연결 리스트(Circularly Doubly Linked List)
양방향 연결 리스트 연산(이동·삽입·탐색·삭제) 및 파이썬 코드로 구현하기
개요
이전 포스팅에서 단방향 연결 리스트(Singly Linked List)에 대해서 알아보았습니다.
연결 리스트를 관리하는 클래스와 각 노드들의 head부터 tail까지 다음 노드의 주소와 key(value)값을 갖고 있는 구조입니다.
참고 : [자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기
다음 노드의 주소만 알고 있기 때문에, 특정 값을 갖고 있는 노드를 탐색하거나 맨 끝의 노드(tail)를 삭제하기 위해서 알아야하는 그 전의 노드(prev)를 찾기 위해 처음부터 탐색해야한다는 단점이 있습니다.
이러한 문제를 보완한 것이 양방향 연결 리스트(Doubly Linked List)입니다.
양방향 연결 리스트(Doubly Linked List)
head 노드부터 탐색하는 것은 O(n)의 시간을 필요로 합니다. 이런 불편함을 해소하기 위해 양방향 연결 리스트는 3개의 구성요소를 갖고 있습니다.
먼저, 노드의 값인 key(value)와 2개의 링크를 갖고 있습니다. 1개는 기존 단방향 연결 리스트의 노드들이 갖고 있었던 앞 노드의 주소 링크이고, 나머지 한개의 링크는 이전 노드의 주소 링크입니다.
이전 노드의 주소를 알고 있기 때문에 tail 노드를 삭제하는 경우 prev노드를 알고 있기 때문에 바로 삭제할 수 있습니다. 그렇다고 해서 양방향 연결 리스트가 무조건 단방향 연결 리스트보다 좋은 것은 아닙니다. 링크를 1개 더 갖기 때문에 연결 리스트의 복잡도가 올라가게 됩니다. 링크가 1개 더 생긴다고 하면 별로 와닿지 않지만, 링크의 개수가 2배가 되는 것이기 때문에, 그 만큼 복잡하고 리소스가 많이 필요하게 됩니다.
이런 단점에도 불구하고 충분한 효율을 얻을 수 있기 때문에 양방향 연결 리스트를 사용합니다.
양방향 연결 리스트를 그림으로 표현하면 다음과 같습니다.

그림을 보시면 가장 왼쪽에 연결 리스트를 관리하는 객체가 있습니다. 이 객체는 연결 리스트의 head의 주소 링크와 전체 크기를 알고 있습니다. 그리고 나서 각 노드들은 이전 노드의 주소 링크와 다음 노드의 주소링크로 연결이 되어 있는 모습을 확인할 수 있습니다.
단방향 연결 리스트와 마찬가지로 tail 노드의 다음 주소 링크는 None(공집합)을 가리킵니다. head의 이전 노드의 주소 링크도 None을 가리키고 있습니다. 양 끝에서 None을 가리키고 있는 모습이 각 끝을 알리는 모습입니다.
우리는 이것을 조금 변형하여 원형 양방향 연결 리스트(Circularly Doubly Linked List)를 만들겁니다.
원형 양방향 연결 리스트(Circularly Doubly Linked List)
원형 양방향 연결 리스트는 기존 양방향 연결 리스트를 동그란 모양으로 만드는 것입니다.
마지막 노드는 None을 가리키고 있었으나, 이것을 첫번째 노드(head)의 주소를 가리키는 것입니다.
그리고 첫번째 노드의 이전 주소를 마지막 노드(tail)를 가리키는 것입니다. 이렇게 되면 다음과 같이 원형의 모양을 띄게 됩니다.
이렇게 동그란 모양을 갖는 연결 리스트가 완성되었습니다.
하지만 이렇게 되면 어디가 처음인지, 마지막인지 구분할 수가 없습니다. 이를 방지하기 위해서 더미노드(Dummy Node)를 추가합니다.
더미 노드는 연결 리스트의 시작점을 알리는 역할로, 맨 앞에 있는 노드입니다. 아무런 값도 갖지 않는(None) 노드이며 연결 리스트가 비어 있는 상황에도 더미 노드가 1개 존재합니다. 이 때, 더미 노드는 다음, 이전 노드를 가리킬 때 자기 자신을 가리키게 됩니다. 연결 리스트의 전체 크기를 카운트할 때는 더미노드를 제외하고 카운트하게 됩니다.
시작점이기 때문에 앞으로는 더미노드는 헤드(head) 노드이기도 합니다.
이제 양방향 연결 리스트를 말할 때는 원형 양방향 연결 리스트라고 가정하고 기술하도록 하겠습니다.
양방향 연결 리스트 연산(이동·삽입·탐색·삭제) 및 파이썬 코드로 구현하기
우선 양방향 연결 리스트를 위에서 배운 개념을 토대로 파이썬으로 구현해보도록 하겠습니다.
위에 Node 클래스는 기본적인 노드들의 정보를 기록하는 클래스이고, DoublyLinkedList 클래스는 연결 리스트를 관리하는 클래스입니다.
Node 클래스의 경우 각 노드의 키(value)값, 다음 노드의 주소, 이전 노드의 주소 값을 갖고 있습니다. DoublyLinkedList 클래스는 연결 리스트의 첫번째 노드인 head의 주소와 전체 연결 리스트의 크기값을 갖고 있습니다.
맨 처음 연결 리스트가 생성되면 더미 노드(head 노드)를 생성합니다. 더미 노드는 크기를 카운트할 때 포함되지 않으므로 연결 리스트의 크기는 0으로 초기화됩니다. 단방향 연결 리스트에서 보셨듯 __str__ 메소드의 경우 출력할 때 어떤 값을 출력할지에 대한 메소드입니다. 키값을 알고 싶기 때문에 키값을 반환하도록 했습니다.
__iter__ 메소드의 경우 이터레이터를 활용하여 for 문을 사용할 수 있도록 하는 메소드라고 배웠습니다. yield는 일종의 return(반환형)으로 각 값을 넘겨주는 역할을 합니다.
참고 : [자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기
양방향 연결 리스트의 연산
이제 양방향 연결 리스트의 연산에 대해서 알아보도록 하겠습니다.
생성된 연결 리스트를 이동하거나 다른 리스트에 옮겨서 이어서 연결할 수 있습니다. 이를 위해서 해당 노드를 찾기 위한 탐색 연산이 필요하고, 필요 없는 노드는 삭제할 수 있습니다.
Splice 연산
양방향 연결 리스트의 연산은 대부분 Splice 연산을 이용합니다. 계속해서 응용할 수 있기 때문에 아주 중요한 역할을 합니다. Splice 연산은 일정 구간을 떼서 특정 노드에 옆에 추가하는 것을 의미합니다.
이를테면, 다음과 같이 사용할 수 있습니다.
splice(a, b, x)위와 같이 3개의 파라미터(매개변수)가 주어집니다. 그럼 a~b 구간을 잘라서 x의 다음 자리(next)에 추가하는 것입니다.
이때 x는 같은 연결리스트 내에 있을 수도 있고, 다른 연결 리스트일 수 있습니다. 어디든 잘라서 이어 붙일 수 있다는 뜻입니다.
다음과 같이 2개의 연결 리스트가 있다고 가정하겠습니다.
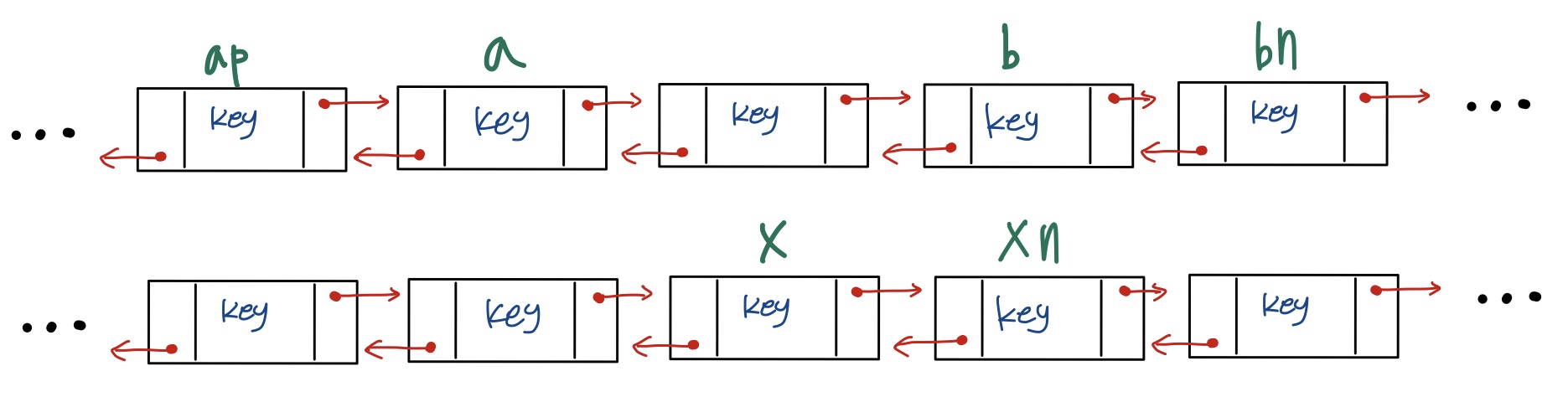
각 연결 리스트는 a와 b를 포함한 것과 x를 포함한 것, 총 2개의 연결 리스트가 있습니다. a의 이전 노드 ap, b의 다음 노드 bn, x의 다음 노드 xn 이라고 이름을 붙였습니다.
해당 연결 리스트에 splice 연산을 해서 a~b 노드를 x 다음에 연결하려고 합니다. 그럼 어떤 변화가 일어날까요?
노드를 옮기는 것은 연결 링크만 변경하면 됩니다. ap의 다음 링크가 bn을 가리키고, bn의 이전 링크가 ap를 가리키면 해당 연결 리스트에서 a~b를 잘라낼 수 있습니다.
잘라낸 a~b 구간을 x 다음에 추가하려면 x의 다음 링크가 a를 가리키고, xn의 이전 노드가 b를 가리키면 a~b구간을 x 다음으로 추가할 수 있습니다. 그림으로 보면 다음과 같습니다.
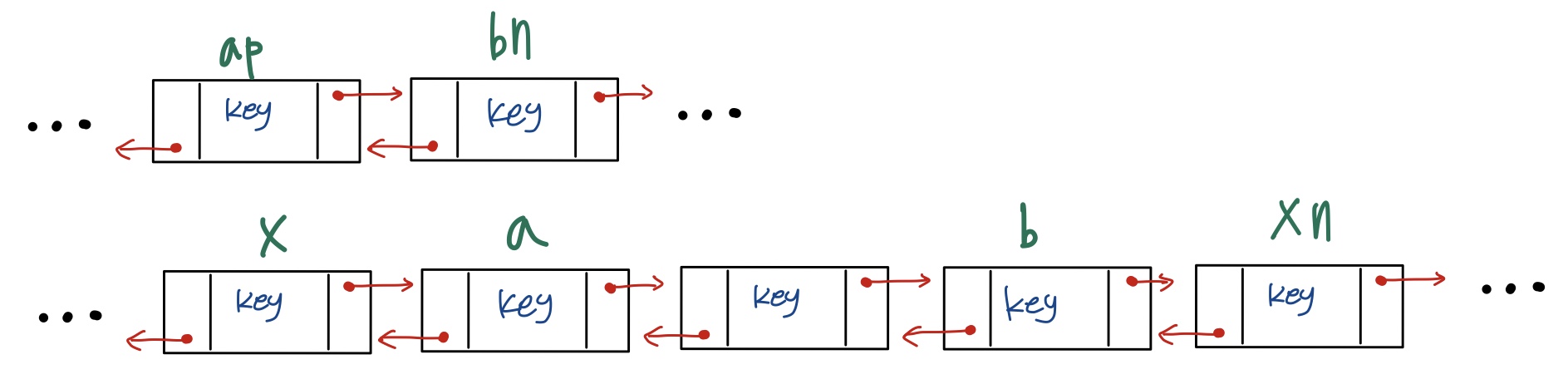
이렇게 일정 구간을 잘라서 특정 위치로 이동하는 것이 splice 연산입니다. 보시면 총 6개의 링크를 변경해서 연산을 진행할 수 있습니다. 이 내용을 코드로 작성해보도록 하겠습니다.
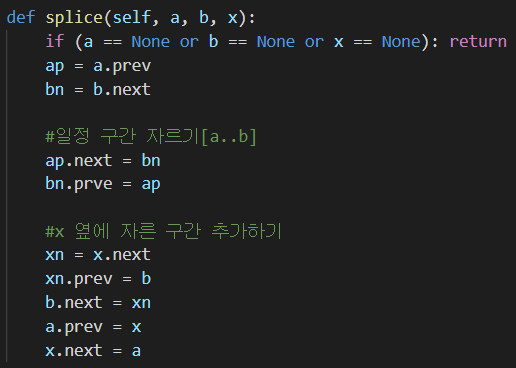
앞서 말씀드린 내용을 코드로 옮긴 것입니다. 맨 처음 조건문이 추가되었는데, 파라미터로 받은 3개의 노드 중 한 개라도 존재하지 않으면 연산을 진행할 수 없습니다. 이 경우에는 아무런 연산도 취하지 않고 메소드를 종료하고 리턴하게됩니다.
이 외에도 Splice 연산을 사용하기 위해서는 다음 조건에 부합해야합니다.
조건 1: a 노드 다음에 b 노드가 존재한다. (바로 옆이 아니어도 상관없음)
조건 2: a 노드와 b 노드 사이에 head(더미) 노드가 존재하지 않는다.
조건 3: a 노드와 b 노드 사이에 x 노드가 존재하지 않는다.
다소 헷갈릴 수 있으나 천천히 보면 쉽게 이해할 수 있는 내용입니다.이 Splice 연산을 통해서 다양한 연산을 할 수 있습니다.
이동 연산
먼저 노드를 이동하는 이동 연산입니다. 이동 연산의 경우 splice 연산을 활용하면 아주 간단하게 해결할 수 있습니다.
splice 연산에서 일정 구간을 나누는데, 이 구간을 1개의 노드만 선택하면 이동 연산에 활용할 수 있습니다.
특정 노드 앞으로 이동하는 moveAfter , 뒤로 이동하는 moveBefore 메소드를 작성해보도록 하겠습니다.

보시듯 Splice 연산을 활용하면 1줄 내지 2줄로 이동연산을 쉽게 할 수 있습니다.
삽입 연산
특정 노드를 삽입하는 것도 간단하게 해결할 수 있습니다. 원하는 키 값을 가진 노드를 생성해서 원하는 위치에 삽입(이동)해서 해결할 수 있습니다. 마찬가지로 특정 노드 앞으로 이동하는 insertAfter, 뒤로 이동하는 insertBefore을 작성해보겠습니다.
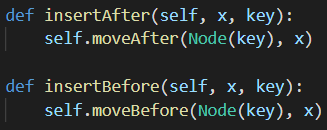
이동 연산을 활용해서 1줄로 쉽게 해결할 수 있습니다. 같은 맥락으로 맨 앞에 노드를 추가하는 pushFront와 뒤에 추가하는 pushBack도 작성할 수 있습니다.

보시는 것처럼 삽입 연산을 활용해서 push 연산을 진행할 수 있습니다. pushBack을 insertBefore 메소드를 활용할 수 있는 이유는 원형 양방향 연결 리스트이기 때문입니다. head 노드의 이전 주소 링크는 tail 노드의 주소를 갖고 있기 때문에 이와 같이 해결할 수 있습니다.
탐색 연산
그 다음은 특정 노드를 찾는 탐색 연산을 진행해보도록 하겠습니다. 맨 처음 노드인 head 노드(더미 노드)부터 맨 끝 tail노드까지 탐색을 진행해야 합니다. 현재 연결 리스트는 원형이기 때문에 맨 마지막 노드까지 돌고 나면 다시 head 노드로 돌아오게 됩니다. 이 점을 이용해서 탐색 연산을 진행할 수 있습니다.

head 노드부터 탐색을 시작해서 다시 head 노드로 돌아올 때 까지 탐색을 진행합니다. 찾는 노드가 있는 경우 해당 노드를 리턴하고, 그렇지 않은 경우 None을 리턴하게 됩니다.
삭제 연산
마지막 삭제 연산입니다. 예를 들어, A 노드를 삭제한다고 가정하겠습니다. A 노드의 이전에 존재하는 노드를 AP, 이후에 존재하는 노드를 AN 이라고 하겠습니다. A 노드를 삭제하기 위해서는 AP의 다음 주소 링크가 AN이 되어야 하고 AN의 이전 주소 링크가 AP로 변경되면 A 노드는 더 이상 연결 리스트에 존재하지 않습니다.

해당 내용을 코드로 작성한 것입니다. x 노드가 존재하지 않거나 더미노드일 경우 삭제할 수 없기 때문에 아무 연산도 하지 않고 return 후 함수를 종료합니다. 그렇지 않은 경우 xp, xn의 주소 링크를 변경하고 x를 메모리 상에서 삭제합니다.
이상으로 양방향 연결 리스트의 기본 연산을 마무리 하겠습니다.이외에도 popFront, popBack, join, split 연산이 존재하지만, 포스팅이 너무 길어지기 때문에 이후에 다루도록 하겠습니다.
각 연산의 시간 복잡도
연산에 대해서 알아보았는데 각 연산의 시간 복잡도는 어떻게 될까요?
대부분의 연산은 Splice 연산을 활용합니다. Splice 연산은 6개의 링크만 변경하면 되기 때문에 상수 시간 내에 해결할 수 있습니다. 따라서, 시간 복잡도는 O(1)이 됩니다.
Splice만으로 해결할 수 있는 이동, 삽입연산은 마찬가지로 O(1)입니다.
삭제연산은 2개의 링크만 변경하면 되기 때문에 상수 시간 내에 해결할 수 있으므로 O(1)입니다. 하지만, 삭제하려는 노드를 찾기 위해서는 탐색 연산도 해야합니다. 탐색 연산은 모든 노드를 다 탐색해야할 수 있기 때문에 O(n)입니다.
정리
이상으로 양방향 연결 리스트에 대한 포스팅을 마무리하겠습니다.
시간에 여유가 생긴다면 여태까지 배운 순차적 자료구조인 배열, 단방향 연결리스트, 양방향 연결리스트의 시간 복잡도를 비교해서 정리해보도록 하겠습니다.
*한국외대 신찬수 교수님의 Data Structures with Python 강의를 참고하여 포스팅하였습니다.
'Computer Science > 자료구조' 카테고리의 다른 글
| [자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기 (0) | 2021.08.23 |
|---|---|
| [자료구조] 큐(Queue)란? (0) | 2021.08.19 |
| [자료구조] 스택 예제, 중위 표기(infix)를 후위 표기(postfix)로 변환하기 (2) | 2021.08.16 |
| [자료구조] 스택(Stack)이란? 스택을 활용해 괄호쌍 확인하기 (0) | 2021.08.11 |
| [자료구조] 순차적 자료구조, 배열과 리스트의 이해 (0) | 2021.08.10 |
![[자료구조] 단방향 연결리스트(Singly Linked List)란? 파이썬으로 구현하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FJtZ0V%2FbtrjPNnSwEB%2Fck92cL1LlcM46FASUTKFIK%2Fimg.png)
![[자료구조] 큐(Queue)란?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbyJG3q%2FbtrcB4Cu3S6%2FzyvKG5T1nvsSK5whcKp3ZK%2Fimg.png)
![[자료구조] 스택 예제, 중위 표기(infix)를 후위 표기(postfix)로 변환하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FVLbAm%2Fbtrb7z56KHB%2FuXtwbyT1fO3Bj7CZmYGae0%2Fimg.png)
![[자료구조] 스택(Stack)이란? 스택을 활용해 괄호쌍 확인하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2F3Xs32%2FbtrbLd2jPQq%2FJK93n2kZIn4KS3cHaQDn60%2Fimg.png)